semanticClimate | Making knowledge open, machine-readable and actionable
#SemanticClimate focuses on semantifying climate data and resources to make climate knowledge open, machine-readable, and actionable. Our Idea is to help scientists, policymakers, and communities respond more effectively to climate change, but more importantly, our aim is to create Youth Knowledge Champions, so that together, we can take Climate Action to each and every citizen in the world.
Our Approach
We work by creating, distributing and using software.
We are involved in making climate knowledge semantic and by semantic we mean there's a formal structure to the documents or other informations in which specific terms are linked to definitions particularly in Wikimedia such as Wikidata or Wikipedia. These documents are described as a five-star document in Tim Berners-Lee's approach. That is it's open, it's semantic, and it can be embedded in the linked open data graph of the world of which Wikidata is the epitome with about 100 million nodes in that.
How do we work?
We work as an online team with a group of interns probably every 2 or 6 months, with frequent sessions on Zoom, underpinned with Slack and daily commits to repositories on Github following ONS philosophy (commit immediately for the whole world to see, “no insider knowledge”). The primary recording medium is Github repositories for programs, documents, discourse.
The interns come in with a lot of different backgrounds, not knowing what Python is, and some people come in with a huge amount of knowledge. We work very much by, communal activity, so people will help each other to do things.
We are driven by two main goals:
- To make climate knowledge accessible to as many people as possible
- To show the semantic approach and how it works
The complete package (documents, software, learning protocols) is aimed at several demographics (young people, retired people, those with English as Second Language (ESL)).
The tools we utilize and are actively working on developing.
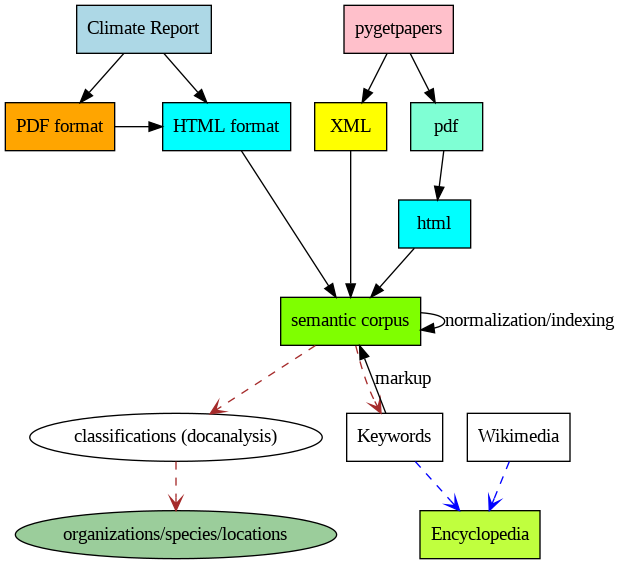
Our work at semanticClimate is mainly around the tool set for the content retrieval, creating what we call a corpus or mini corpus of IPCC reports and then some amplification of that.
Our codes are developed in Python and we demonstrate via colab notebook/Jupyter notebook.
Here are three programs called:
-
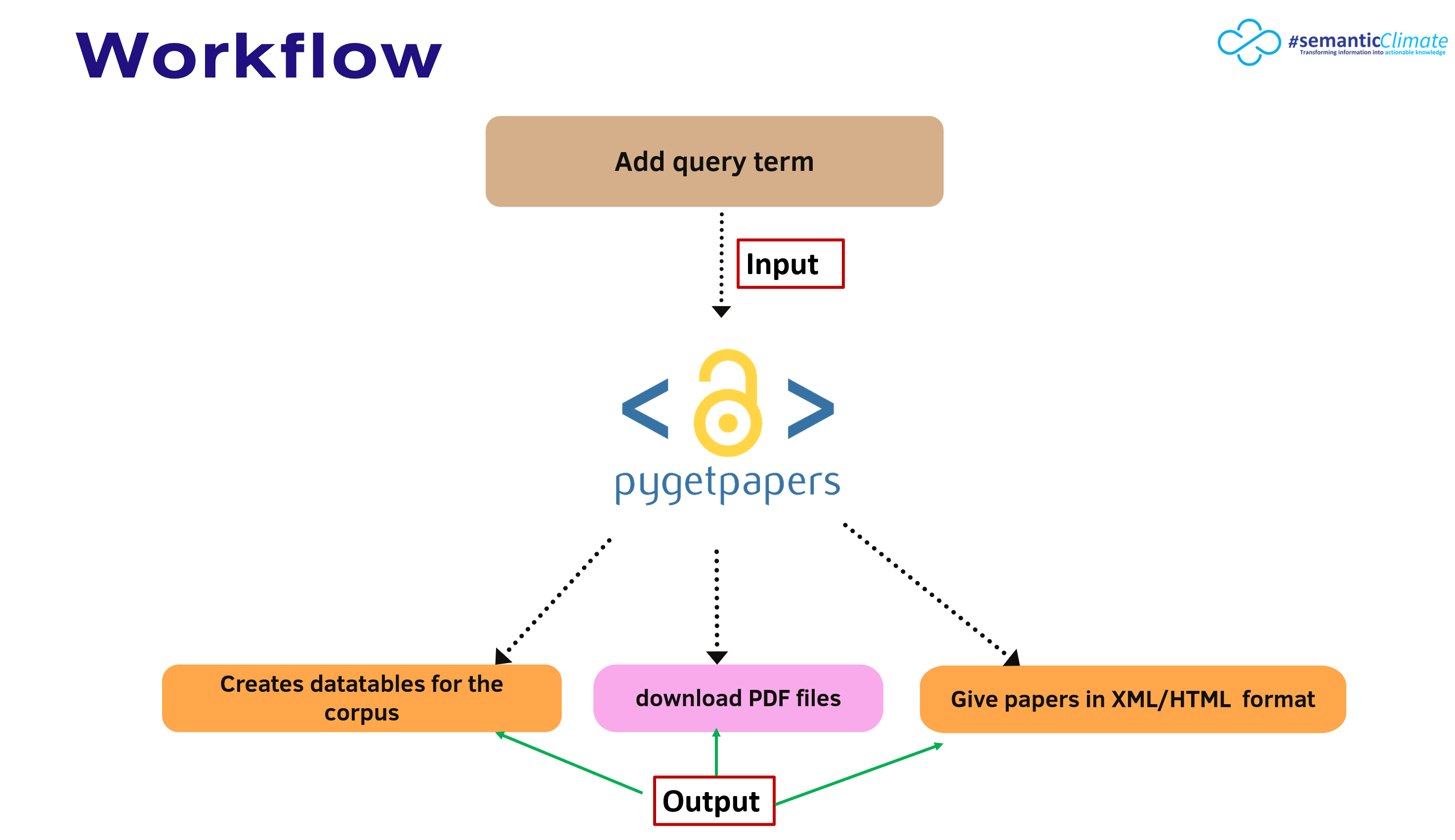
pygetpapers which reads the scientific literature automatically and it is used to query and analyse the current Open scientific literature in bulk. All material was automatically downloaded as JATS XML which are machine readable.
-
docanalysis / NER: for analyzing a collection of articles and extracting information like plant species, locations, chemical compounds, drugs, diseases etc. using dictionaries and these were written by two of our earliest interns.
pygetpapers from Ayush Garg when he's still at school.
docanalysis from Shweata Hegde who did this while an undergraduate.
and the third tool a library of utilities called
- amilib is written by Peter Murray-Rust, which deals with a lot of the integrase and conversion and so on. The tool is used for finding, cleaning, converting, searching, republishing legacy documents (PDF, PNG, etc.) and creating encyclopedia from the keywords.
|
Objectives
-
The ultimate goal is to take the IPCC material and automatically convert it into a standard normalized semantic form.
-
We use HTML as final product and then label it, build dictionaries which are term base on this and label as much as we can.
-
We build knowledge graphs out of that, start to find patterns in the knowledge graphs using machine learning methods.
semantic resources
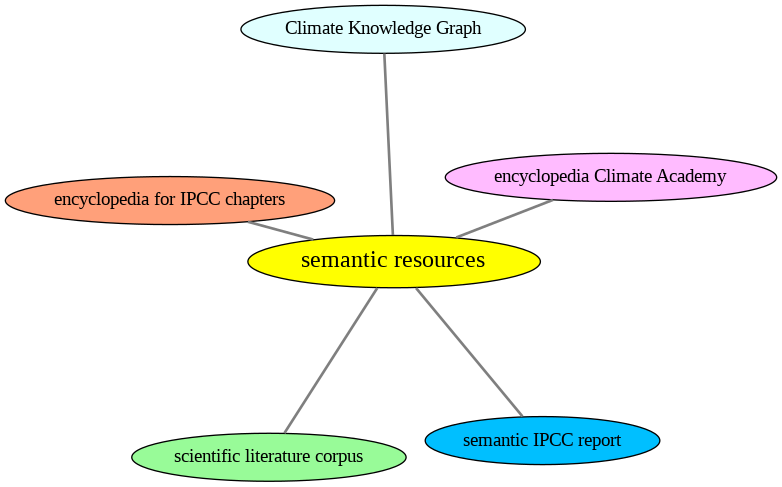
Following resources have been generated by #semanticClimate using in house tools developed by the team to analyze climate reports and data.
|
IPCC corpus:
Analysis of 75 chapters of the UN Intergovernmental Panel on Climate Change. The raw material was automatically converted to semantic HTML and used to create Wikipedia-enhanced dictionaries (one per chapter). The dictionaries were used to search and index the UN IPCC corpus.
scientific literature corpus:
This is created with pygetpapers where we use any keywords to search scientific literatures from the open access journals in the machine-readable form.
encyclopedia – IPCC:
amilib has a tool for rapidly converting a list of words to a dictionary and looking up the terms in Wikipedia.
encyclopedia Climate Academy:
The encyclopedia has been created from the list of climate words and phrases extracted from the very informative book “Climate Academy”.
Climate Knowledge Graph:
The Climate Knowledge Graph (CKG) is an R&D project to make a knowledge graph of the open access parts of the 10,000 page IPCC Sixth Assessment Report (AR6) corpus.
Courses:
FSCI 2025:
The three days course has been organized on the topic “AI — Assisted Literature Review on Open Access Repositories: Including Image and Object Detection”.
sC tools and open literature:
The semantic tools have been applied to do automated literature review in many hands-on workshops in India where people from various backgrounds have learned by doing.
Demonstration
-
Creating machine readable corpus from open access repositories using semantic tool
pygetpapers
|
-
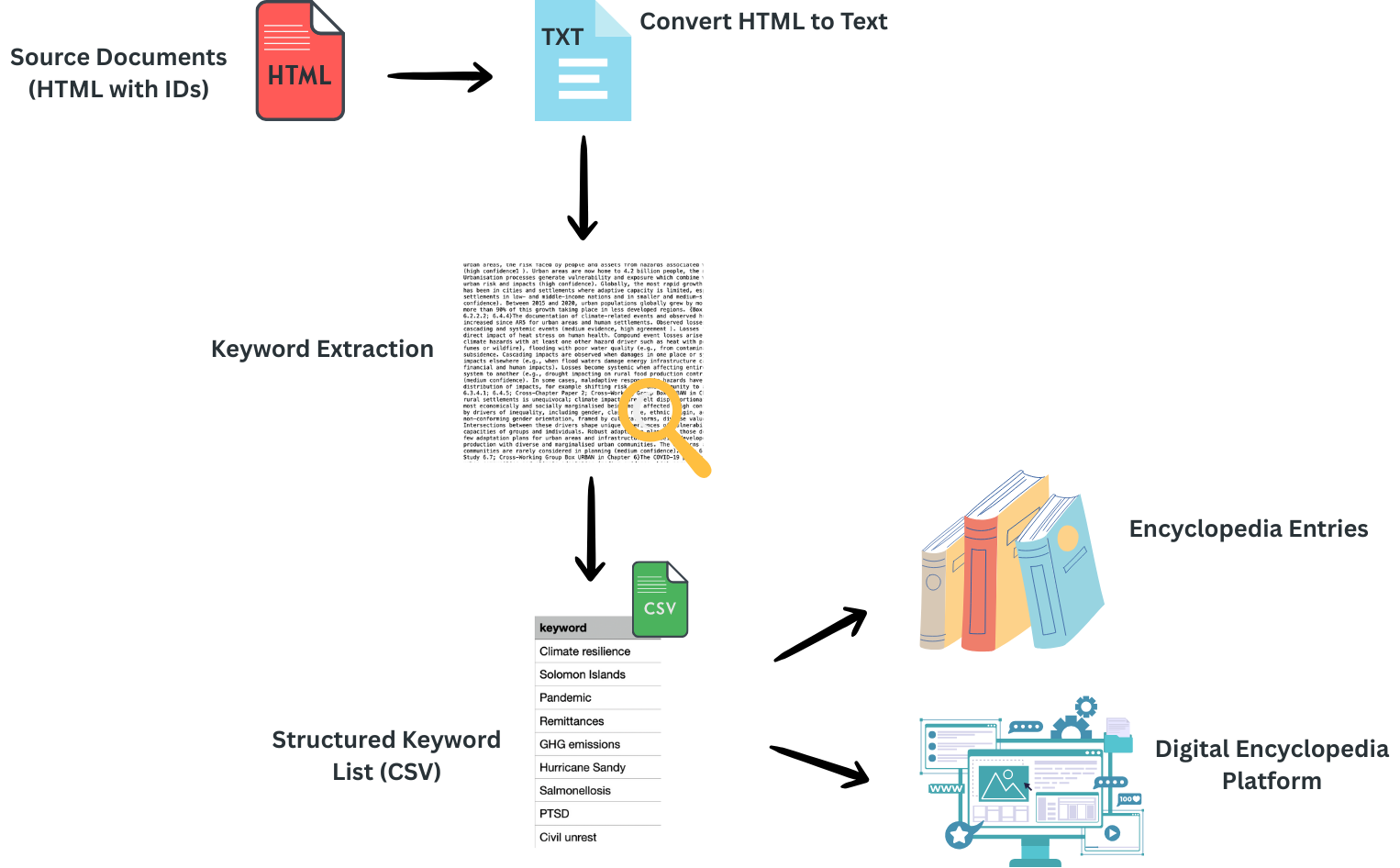
Creating semantic encyclopedia
A comprehensive toolset for extracting and analyzing keywords from scientific documents, with a focus on climate change research and IPCC reports.
It consists of two main subprojects that work together to process scientific documents and extract meaningful insights:
- Keyword extraction
- Encyclopedia
GitHub Repository
Workflow
|
← Back