Event Report | FAIR and Reproducible Structural Biology
Date: 28 January 2026
Organized by BRIC-NIPGR, CODATA INDIA and #semanticClimate
Introduction and Context
The FAIR and Reproducible Structural Biology Workshop was conducted on 28 January 2026 as a full-day online event, hosted under the aegis of the #semanticClimate community. The workshop convened researchers, data specialists, domain scientists, and policy practitioners to discuss and explore emerging challenges in structural biology workflows, particularly focusing on reproducibility, data governance, explainability, and FAIR (Findable, Accessible, Interoperable, Reusable) principles in the context of AI-driven science.
The rapid integration of artificial intelligence (AI) into structural biology for tasks such as protein structure prediction, molecular docking, and simulation-driven discovery, has brought enormous potential for scientific breakthroughs. However, it has also exposed limitations in traditional scientific outputs and assessment models, which remain publication-centric and often fail to capture reproducibility, provenance, and metadata standards required for future-ready research. This workshop aimed to address these gaps, demonstrating how FAIR principles can be embedded into complex analytical workflows without compromising intellectual property or data sovereignty.
Objectives and Themes
The workshop was structured around four core objectives:
- Examine AI-driven workflows in structural biology from the viewpoints of provenance, explainability, and reproducibility.
- Explore FAIR and AI-ready metadata frameworks capable of capturing complex simulation pipelines, models, and parameters.
- Discuss innovative research assessment models that go beyond traditional journal and impact factor-based evaluation systems.
- Demonstrate practical use cases of secure, controlled workflow execution and data visitation in real-world structural biology research.
Inaugural Session (10:00 AM – 11:15 AM IST)
Intro to AI Impact Pre-Summit
The inaugural session set the scientific and policy context for the workshop, highlighting the transformative role of Artificial Intelligence (AI) in structural biology and drug discovery, while emphasizing the need for reproducibility, FAIR data practices, and responsible research assessment.
-
Dr. Gitanjali Yadav (BRIC-NIPGR) opened the session by introducing the objectives of the AI Impact Pre-Summit. She highlighted the motivation behind organizing the workshop as a preparatory engagement for the India AI Summit 2026, with a focus on aligning AI-driven scientific research with principles of openness, reproducibility, and global equity. She emphasized the role of semantic frameworks and open infrastructure in enabling trustworthy and reusable science.
-
Dr. Narinder Mehra (INSA) presented an overview of CODATA Task Groups, with particular emphasis on the Open Tools and Visitation Frameworks for Global Research Assessment Reform (OT-ViRARe) initiative. He explained how CODATA is working globally to move beyond traditional publication-centric assessment models, advocating for evaluation systems that recognize data, software, workflows, and reproducibility as first-class research outputs.
The inaugural session successfully framed the workshop’s interdisciplinary nature, linking cutting-edge science with policy, governance, and research assessment reform.
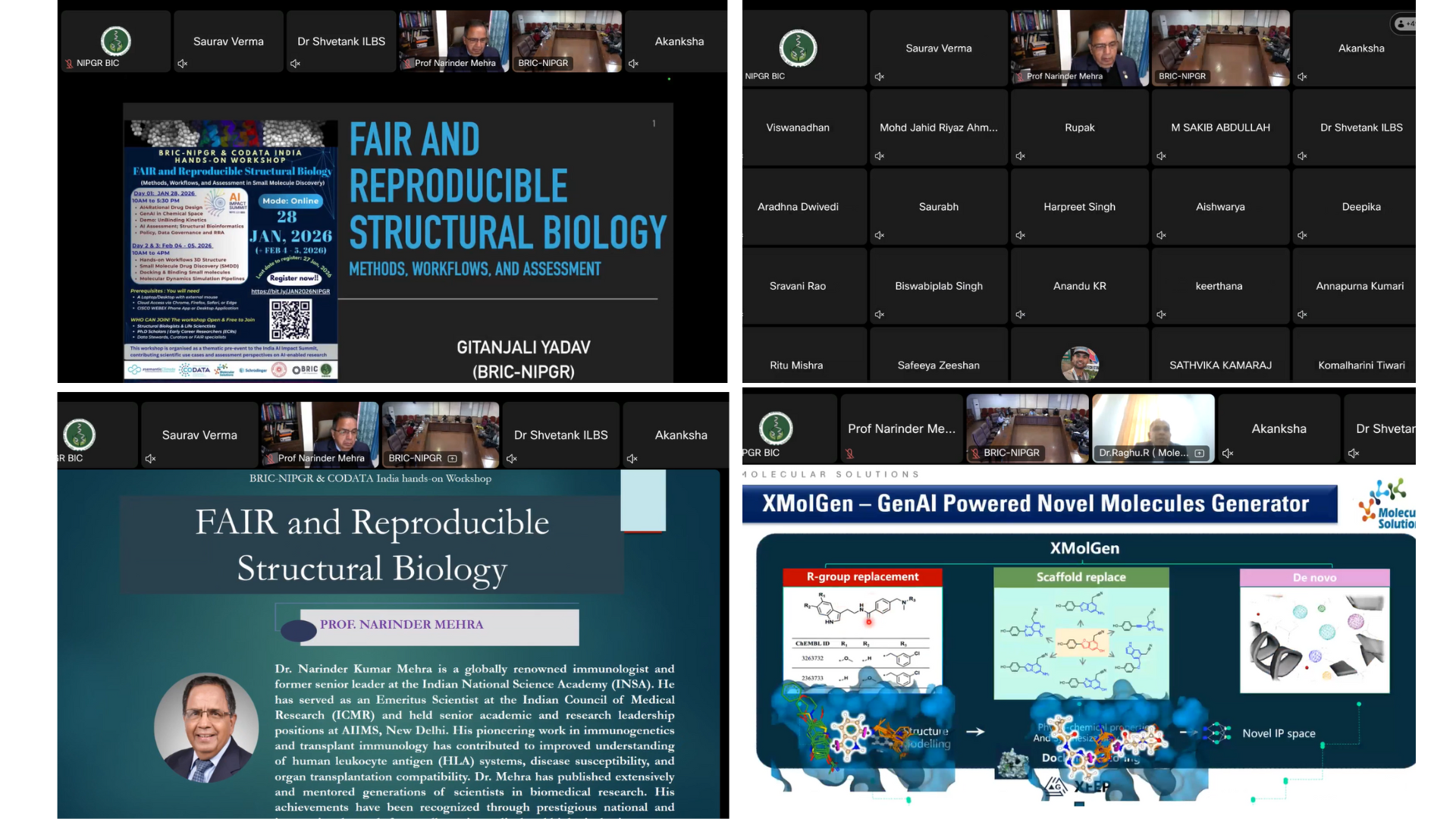
|
-
Recording
Inaugural Session: Introduction to FAIR principles and reproducible practices in structural biology.
Session 1 (11:15 AM – 12:00 PM IST)
How AI/ML and Rational Drug Design are Transforming Drug Discovery
- Speaker: Dr. Raghu R., CEO, Molecular Solutions Software Pvt. Ltd.
This session provided an industry-oriented overview of how AI, machine learning, and rational drug design methodologies are reshaping the drug discovery pipeline. Dr. Raghu explained how computational approaches are significantly reducing timelines from target identification to lead optimization while improving prediction accuracy.
He has explained about the Gen AI in lead identification and optimization, AI in ADMET, in patent analysis, AI in 100% accurate polymorph prediction etc. The brief overview of the tool ADMET Predictor was also provided to the researchers.
-
Recording
Session 1: How AI/ML and Rational Drug Design are Transforming Drug Discovery.
Session 2 (12:00 PM – 01:00 PM IST)
Fundamentals of Generative AI and Ultra-Large Chemical Space Docking
- Speaker: Dr. Faizan Syed, Applications Scientist (Presentation and Live Demonstration)
Session 2 focused on the technical foundations of Generative AI and ultra-large chemical space docking methods. Dr. Faizan explained the fundamentals of structure-based design using SeeSar and Ultra-Large Chemical Space Docking. He talked about FlexX (ligand docking tool) and its core mechanism.
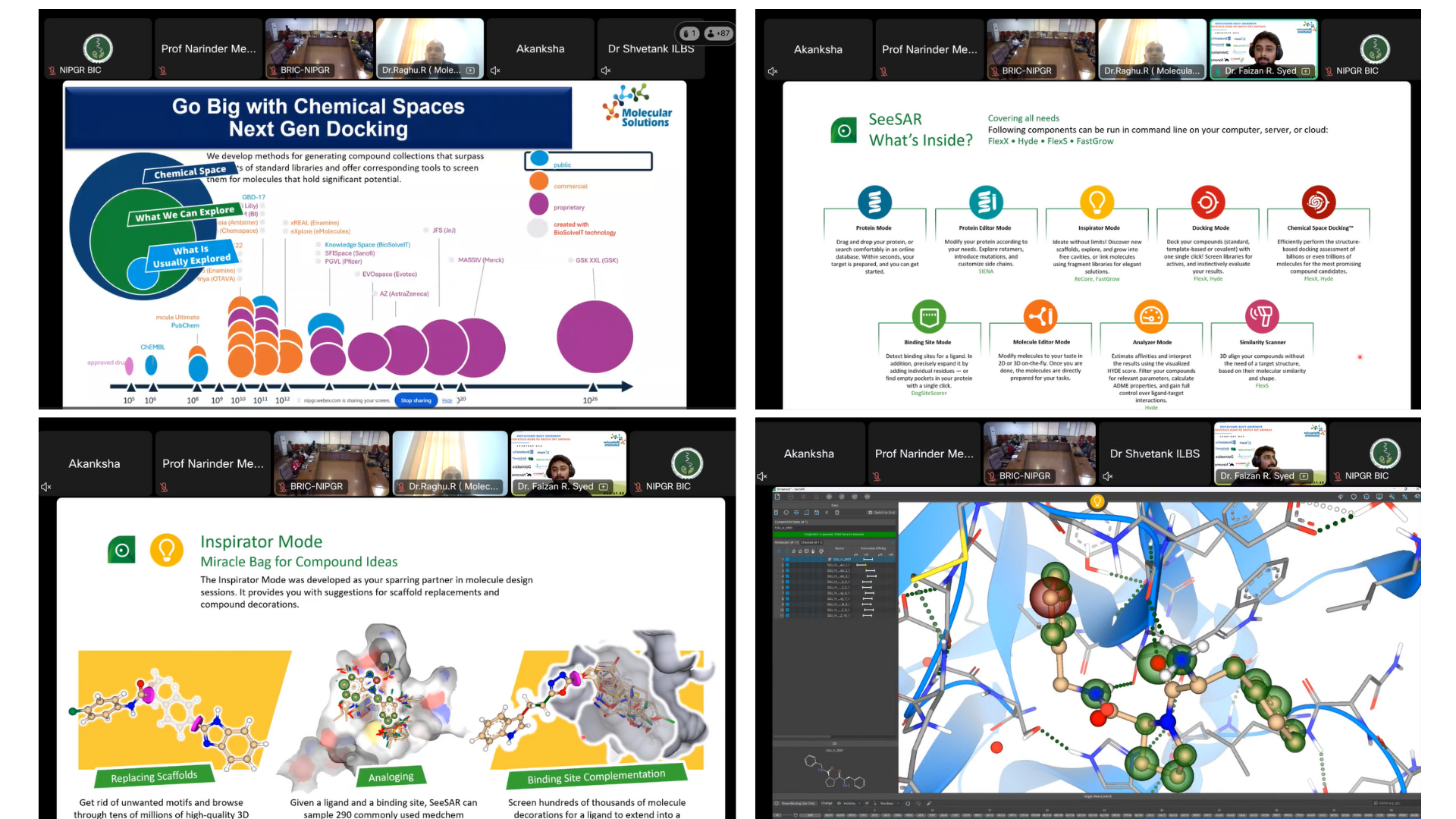
|
-
Recording
Session 2: Fundamentals of Generative AI and Ultra-Large Chemical Space Docking.
Session 3 (02:30 PM – 03:30 PM IST)
How Do We Assess This Work? Beyond Publications and Impact Factors
Prof. Peter Murray-Rust (University of Cambridge) delivered a thought-provoking talk on research assessment reform. He argued that conventional metrics such as journal impact factors fail to capture the full value of modern research outputs, especially in data- and software-intensive AI-driven science. He advocated for assessment frameworks that recognize openness, reproducibility, metadata quality, and machine-readable research objects. He talked about the vision of semanticClimate and how it is working to create semantic and frictionless documents.
-
Recording
Session 3a: How Do We Assess This Work? Beyond Publications and Impact Factors.
This was followed by an interactive audience Q&A session, where participants raised questions on institutional adoption, incentives for open science, and challenges in evaluating non-traditional outputs.
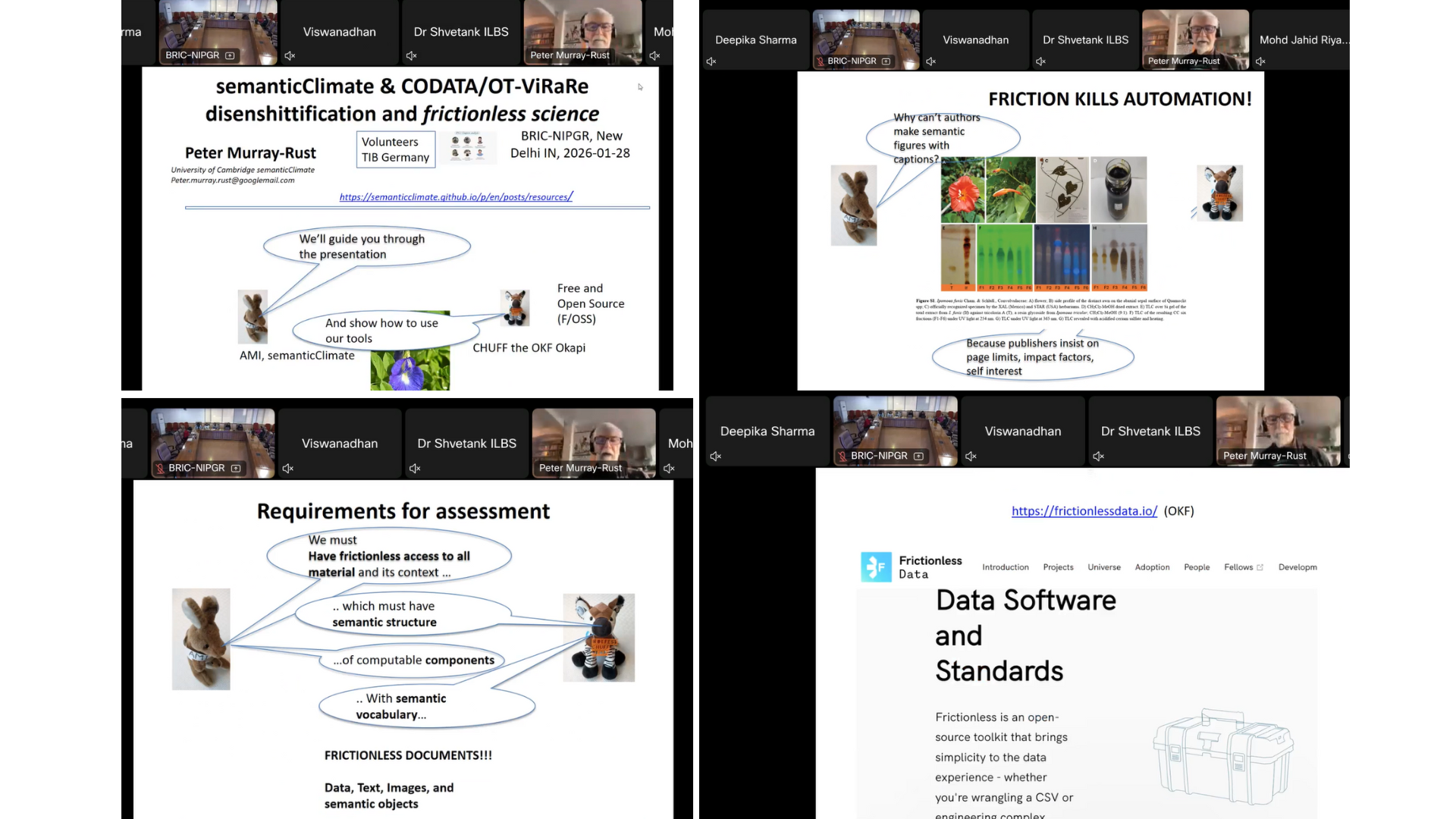
|
|
Mr. Matti Heikkurinen, Project Portfolio Manager, CODATA, discussed ongoing CODATA initiatives aimed at operationalizing responsible research assessment. He highlighted how tools like ORAT can support institutions and funders in implementing fair and transparent evaluation practices.
-
Recording
Session 3b: Discussion on research assessment framework.
|
Session 4 (03:30 PM – 04:30 PM IST)
Accurate Binding Free Energy Predictions and Unbinding Kinetics
-
Speaker: Dr. Viswanadhan, VP, Molecular Solutions
-
Demo and Case Studies: Dr. Anbu Dinesh Jayakumar, Molecular Solutions
This session addressed advanced computational techniques for binding free energy prediction and unbinding kinetics, which are critical for prioritizing drug candidates. Dr. Viswanadhan explained how precise free energy perturbation (FEP) methods improve confidence in ranking ligands across diverse drug targets. He has given an introduction about the workflow for drug design.

|
-
Recording
Session 4a: Accurate Binding Free Energy Predictions and Unbinding Kinetics.
Dr. Anbu Dinesh Jayakumar presented 11 case studies and success stories demonstrating practical applications of these methods in drug discovery. The session highlighted how rapid prediction of binding affinity and unbinding kinetics supports informed decision-making and reduces experimental uncertainty. Importantly, the discussion linked these techniques to issues of reproducibility, provenance, and explainability in AI-driven scientific workflows.
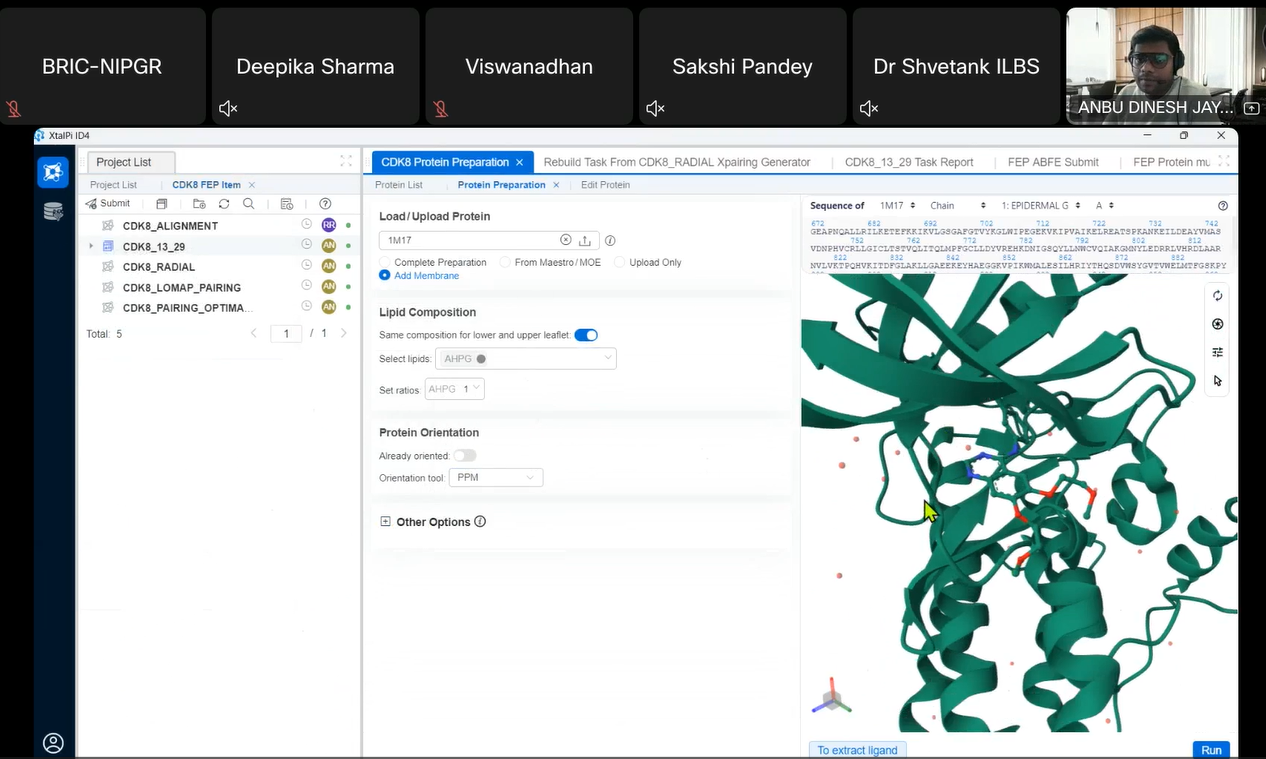
|
-
Recording
Session 4b: Demonstration of the software for Accurate Binding Free Energy Predictions and Unbinding Kinetics.
Session 5 (04:30 PM – 05:30 PM IST)
Panel Discussion : Reflections for Policy, Data Governance, and ORAT Development
The concluding session was a panel discussion moderated by Dr. Gitanjali Yadav (BRIC-NIPGR), focusing on policy implications, data governance, and the future development of the Open Research Assessment Toolkit (ORAT).
Panelists included:
- Prof. Peter Murray-Rust, University of Cambridge, UK
- Dr. Bolortuya Ulziibat, Mongolian Academy of Sciences
- Dr. Debasisa Mohanty, Director, BRIC-NII
The panel reflected on lessons from the workshop, emphasizing the need for internationally harmonized metadata standards, trusted AI workflows, and assessment systems aligned with open science principles. Discussions highlighted the importance of capacity building in the Global South and the role of collaborative, community-driven frameworks in shaping responsible AI-enabled research.
Following are the few questions discussed with the panellist.
-
How do we think about reproducibility when models, parameters, and compute environments matter as much as datasets? What should be recorded, and what should be assessed?
-
There is a need to expand AI driven research in Academia, especially in tier2, Tier3 educational institutes in India through shared infrastructure and resources ( including Human Resources).
-
We should develop strategies to build country-wise data accuracy systems.
-
Recording
Session 5: Panel Discussion-Reflections for Policy, Data Governance, and ORAT Development.
The session concluded with consensus on the need to integrate scientific practice, policy, and governance to ensure that AI advances lead to equitable, transparent, and reproducible science.
← Back